지난글: https://powderblue0.tistory.com/1
[데이터분석] Titanic 데이터셋: 결측치 처리
안녕하세요. 티스토리 블로그로 다시 돌아왔습니다.아무래도 네이버 블로그보다는 티스토리로 갈아타는게 좋아 보였어욯ㅎㅎ 근황토크)) 몇주간 통계학이랑 Adsp 공부를 하느라 바빠서(사실 공
powderblue0.tistory.com
지난 글에서의 Titanic 데이터셋의 결측치 처리에 이어 전처리 과정을 조금 더 진행해 보도록 하겠습니다.
결측치 처리를 하였으니 (이상치 탐색은 Pass하고), 이번 글에서는 모델 훈련에 앞서 Feature Engineering을 진행해 보도록 합니다.
참고한 코드 링크 올려두겠습니다!!
https://www.kaggle.com/code/gunesevitan/titanic-advanced-feature-engineering-tutorial
Titanic - Advanced Feature Engineering Tutorial
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
Feature Engineering이란?
: 머신러닝 알고리즘의 성능을 향상시키기 위하여 데이터에 대한 도메인 지식을 활용하여 변수를 조합하거나 새로운 변수를 만드는 과정
Target열인 Survived는 이진 분류 문제이므로, Decision Tree나 Random Forest 등의 모델을 사용을 염두에 두고 Feature들을 범주화하는 방향으로 전처리를 진행하였습니다.

목차
1. Target 열에 따른 시각화
1.1. 연속형 데이터 시각화
1.2. 범주형 데이터 시각화
2. Feature Engineering: 연속형 데이터 범주화(Binning)
3. Feature Extraction(1): Parch&SibSp를 Family로 변환
4. Feature Extraction(2): Name에서 Title 추출
5. Feature Extraction(3): Ticket으로부터 Ticket Frequency 추출
6. 피쳐 엔지니어링 결과 정리
7. Feature Encoding: 라벨인코딩 및 원핫인코딩 진행
1. Target 열에 따른 시각화
피쳐 엔지니어링을 진행하기 이전에, 결측치 처리 후의 데이터셋에 대해 타겟열인 Survived열을 기준으로 연속형 데이터와 범주형 데이터를 시각화해 보았습니다.
데이터셋에는 다음과 같은 Feature들이 존재합니다.
- 연속형 데이터: Age열, Fare열
- 범주형 데이터: Embarked열, Parch(부모/자녀수)열, SibSp(형제/배우자수)열, Pclass열, Sex열, Deck열
1.1. 연속형 데이터 시각화
연속형 데이터인 Age열과 Fare열을 히스토그램 및 추세선으로 시각화한 결과는 다음과 같습니다.
import matplotlib.pyplot as plt
import seaborn as sns
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
sns.histplot(data=df_train, x="Age", hue="Survived", kde=True, bins=30, alpha=0.5,
edgecolor='gray', ax=axes[0], palette=['darksalmon','darkseagreen'])
axes[0].set_xlabel("Age")
axes[0].set_ylabel("Count")
axes[0].set_title("Age Distribution by Survival")
axes[0].legend(labels=['Survived', 'Not Survived'])
# 이하생략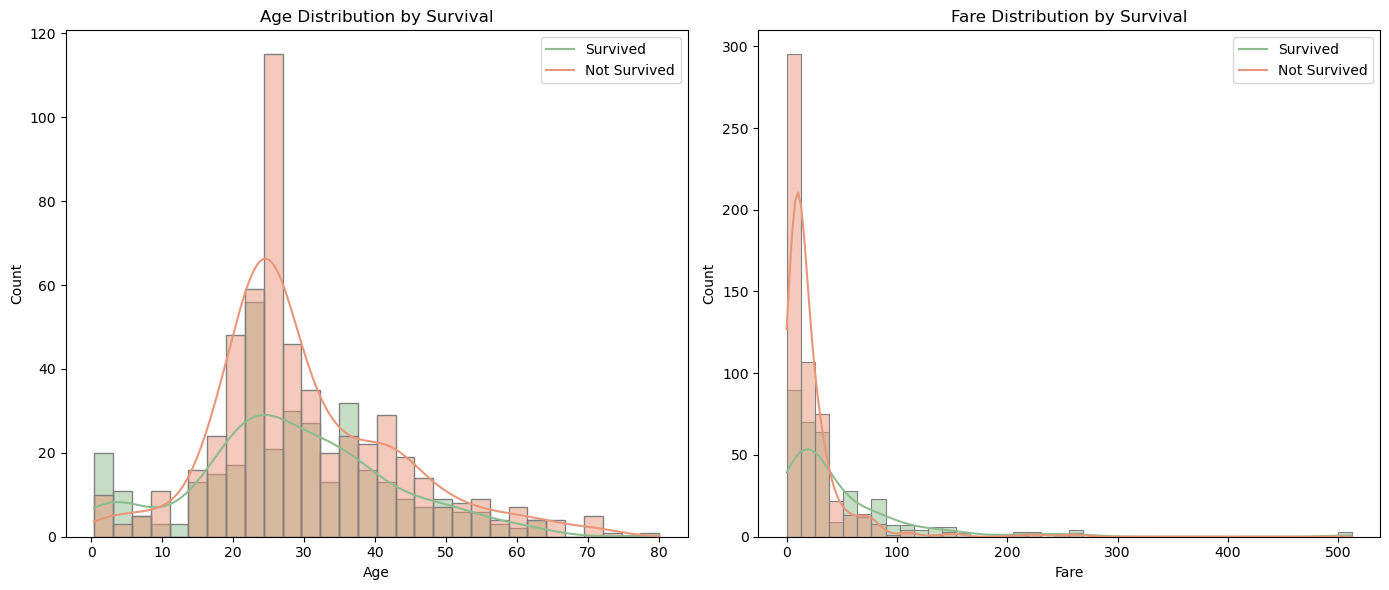
항상 느끼는 거지만 시각화 코드는 손에 익히기 참 어려운 것 같습니다.. 맨날 챗지피티한테 물어물어가며 해결하는중..ㅠ
1.2. 범주형 데이터 시각화
범주형 데이터인 Embarked열, Parch열, SibSp열, Pclass열, Sex열, Deck열을 생존여부에 따라 시각화하는 경우 다음과 같습니다. Not Survived를 빨간색으로, Survived은 초록색으로 칠해봤어요.

2. Feature Engineering: 연속형 데이터 범주화(Binning)
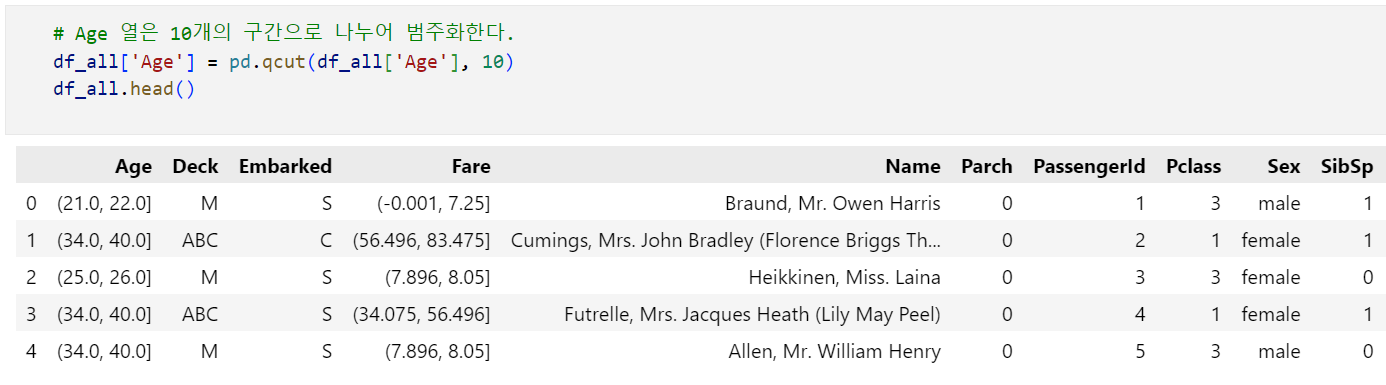
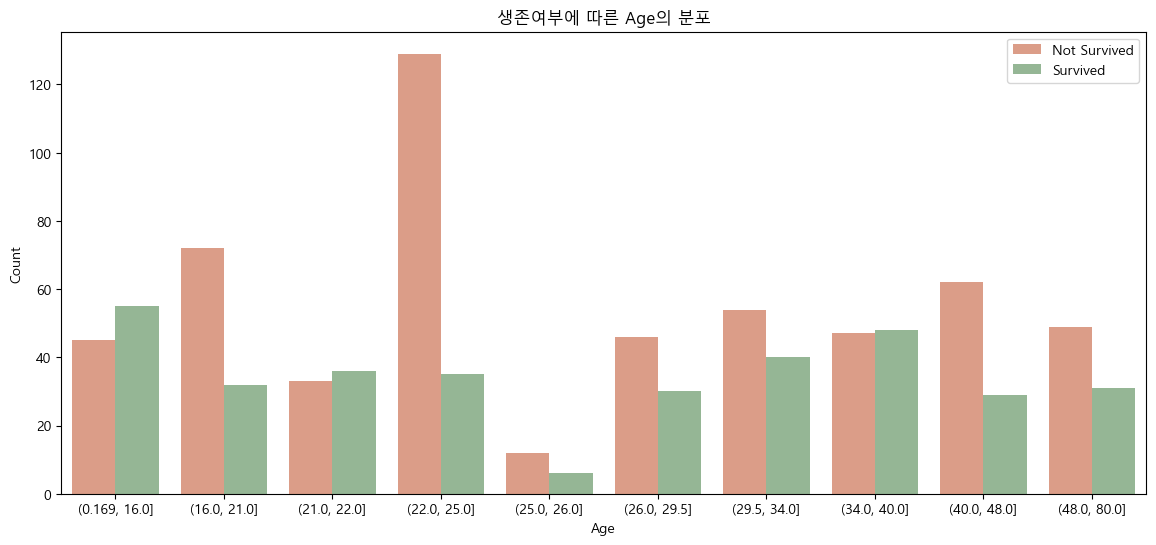
이제 연속형 데이터들을 모두 범주형 데이터로 바꾸어줄 겁니다. 왜냐하면 모델 구축 과정에서 Random Forest를 사용할 것이기 때문이죠. 범주화는 가장 간단한 방법인 Binning을 사용합니다. 별건 아니고 그냥 구간별로 나눠준다는 의미입니다! Fare의 경우 13개 구간으로, Age의 경우 10개 구간으로 나눠줍니다.
Fare열의 경우 범주화 과정은 다음과 같습니다.

코드 주석에 써둔 것과 같이, pd.qcut()을 이용하여 Binning을 진행한뒤 head()를 출력하면 데이터값이 구간으로 출력되는데 이 부분은 이후에 Label Encoding으로 처리해줄 것이기 떄문에 일단 무시해줍니다. Binning 이후의 결과를 그래프로 나타내면 다음과 같습니다.

Age열의 경우에도 같은 방법으로 진행해 줍니다.
Age열을 범주화해주면 밑의 결과와 같이 Age열이 각 사람의 나이가 아닌, '나이 범위'를 데이터로 갖게 됩니다. 즉, 범주화 과정을 통해 우리는 '연령' 데이터에 집중하는 것이 아닌, '연령대' 데이터에 집중하게 됩니다.
3. Feature Extraction(1): Parch&SibSp를 Family로 결합
Feature Extraction(특징 추출) 이란?
: 변수들 사이에 내재한 특성이나 관계를 분석하여 이들을 잘 표현할 수 있는 새로운 선형 혹은 비선형 결합 변수를 만들어 피쳐를 줄이는 방법
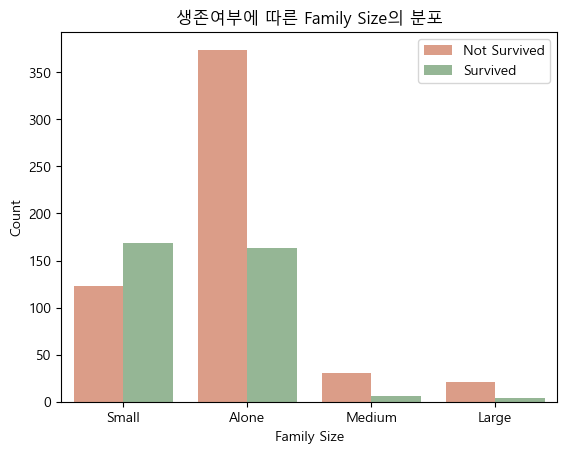
Titanic 데이터셋에는 동승한 부모/자녀수를 나타내는 Parch라는 열과, 동승한 형제/배우자수를 나타내는 SibSp라는 열이 별개로 존재합니다. 타이타닉 데이터셋을 처음 접했을 때도 왜 이 둘이 별개의 열로 존재하는지 이해를 못했었는데 (뭐..나름의 이유가 있었겠죠?) 사실 지금도 이해가 잘 안됩니다. 그래서 그냥 저 두 열들을 결합하여 Family라는 이름의, 동승한 가족 수를 나타내는 새로운 열로 저장하였습니다.
Family 변수는 다음과 같은 과정으로 새롭게 설정하였습니다.
- (가족 구성원 수) = (부모/자녀수) + (형제/배우자수) + 1
- Family변수: 가족 구성원 수가 1인 경우 Alone, 2~4인 경우 Small, 5~6인 경우 Medium, 7~11인 경우 Large를 할당
df_all['Family'] = df_all['SibSp']+df_all['Parch']+1
df_all['Family'] = df_all['Family'].replace([1], 'Alone')
df_all['Family'] = df_all['Family'].replace([2,3,4],'Small')
df_all['Family'] = df_all['Family'].replace([5,6], 'Medium')
df_all['Family'] = df_all['Family'].replace([7,8,11], 'Large')새로 만든 변수 Family의 분포는 다음과 같습니다.
4. Feature Extraction(2): Name으로부터 Title 추출
전처리 과정에서의 가장 중요한 건 '살릴 수 있는 건 최대한 살리는' 것이라고 생각합니다.
Titanic 데이터셋의 Name열은 얼핏 보면 타겟열과 무관한 노이즈처럼 보일 수 있으나 조금만 살펴보면 사람들의 각 이름에 Mr, Mrs, Miss 등이 포함되어 있어 이를 통해 공통된 특성을 추출 가능하다는 사실을 알 수 있습니다. Mr, Mrs, Miss등을 추출하여 Title이라는 새로운 변수로 저장해 보았습니다. 코드는 조금 복잡할지도 모르지만... "그것이 코딩이니까."
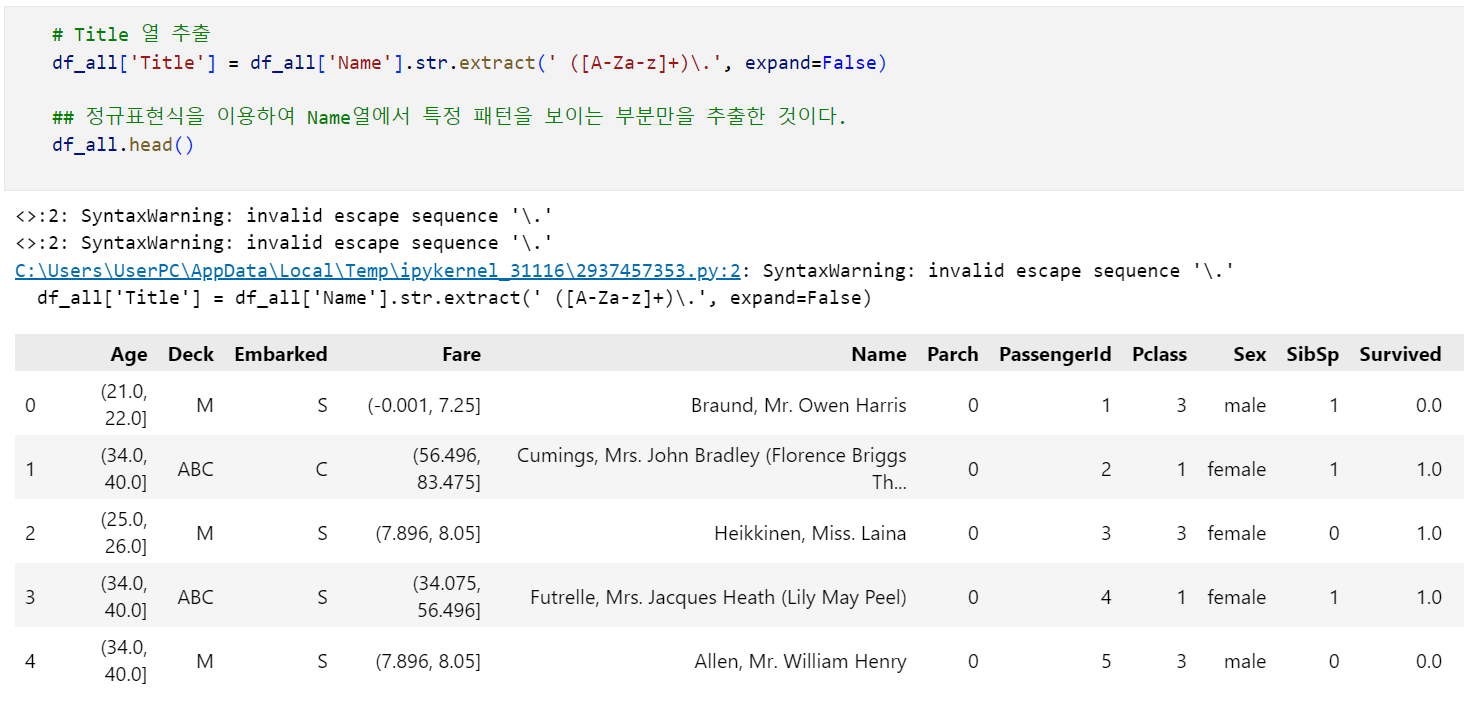
코드를 어떻게 써야할지 고민하다가 정규표현식을 사용한 누군가의 코드를 훔쳐왔습니다. (코드줍줍) 다음 코드를 통해 '공백 뒤 마침표를 포함한 영단어'의 패턴을 찾을 수 있습니다. (사실 잘 이해 못함)
이렇게 추출한 Title 열을 확인해보면 다음과 같습니다.
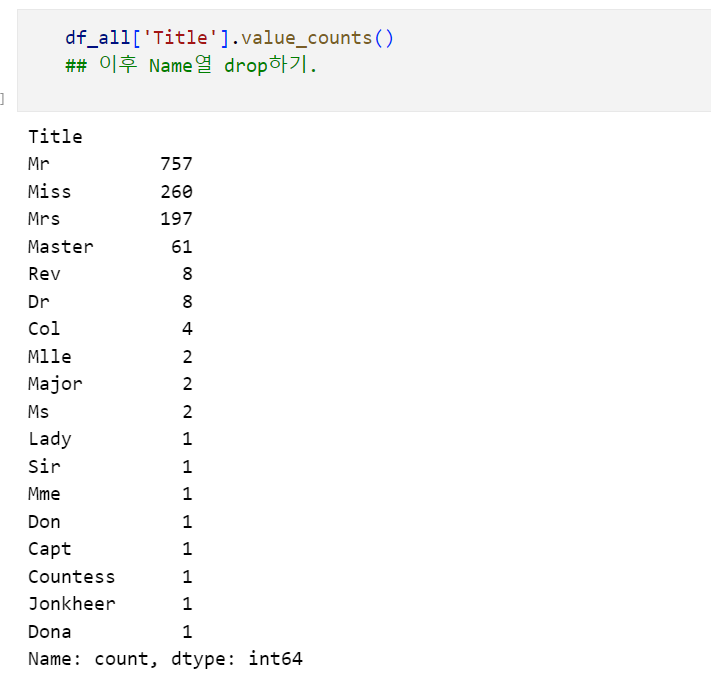
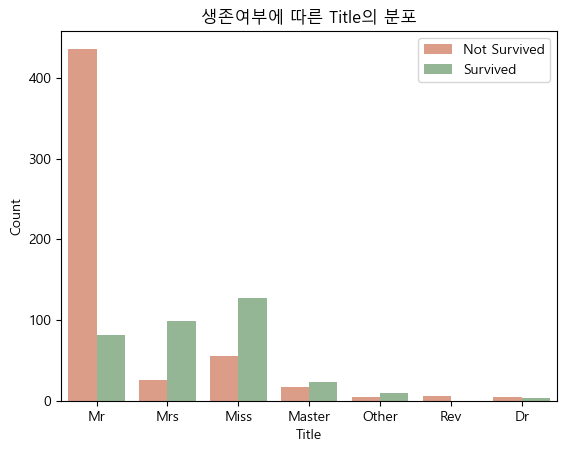
대부분 Mr, Miss, Mrs, Master, Rev, Dr에 속하므로, 나머지 Col, Mlle, Major, Sir 등은 Other로 분류해 주었습니다. 생존여부에 따라 Title을 시각화하면 다음과 같습니다.
5. Feature Extraction(3): Ticket으로부터 Frequency 추출
지금까지의 과정을 통해 Titanic 데이터셋에서 타겟열인 Survived를 제외하고 Age열과 Fare열, Embarked열, Title열, Pclass열, Sex열, Family열, Deck열을 모두 범주형 데이터로 만드는 데에 성공하였습니다. 이제 남은 열인 Ticket을 처리하는 과정을 진행해보려 합니다.
Ticket열은 타겟열과 아무런 관련이 없는 노이즈인 것처럼 보이지만, Ticket열의 '중복된 정도'를 통해 유의미한 특성을 추출 가능합니다. 동승한 일행의 경우 동일한 Ticket 값을 갖기 때문에, Ticket의 중복된 정도를 나타낼 경우 이는 Family와 비슷하게, '동승한 일행 수'를 나타내는 데이터로 기능하게 됩니다. 이에 따라 Ticket 값의 중복된 정도를 Ticket Frequency라는 새로운 열로 변환해 보았습니다.
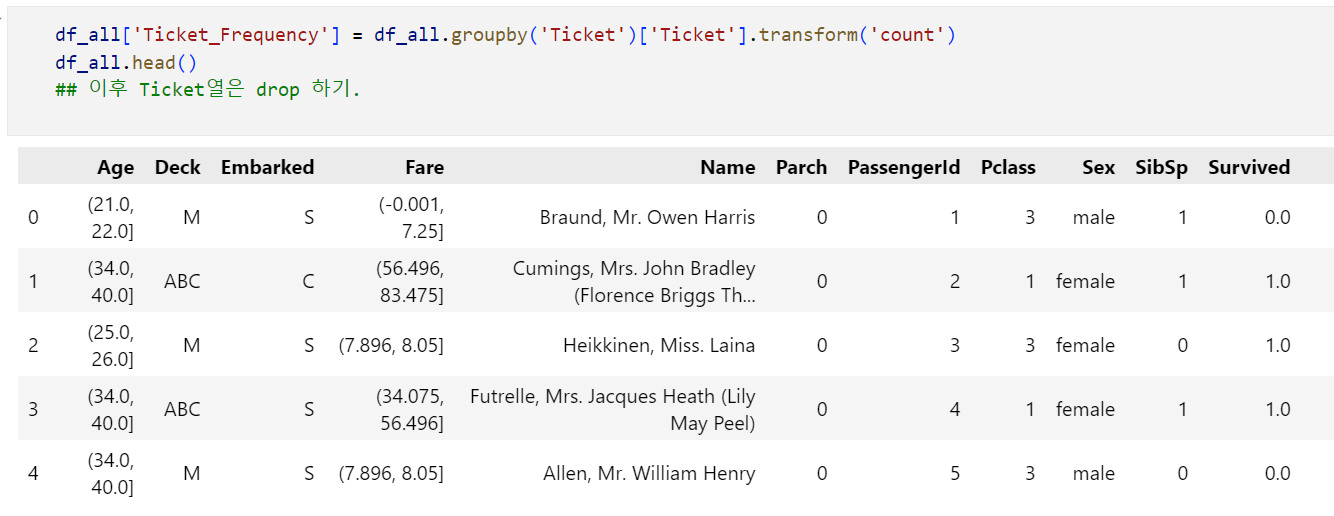
새롭게 추출한 Feature를 확인해보면 다음과 같습니다.
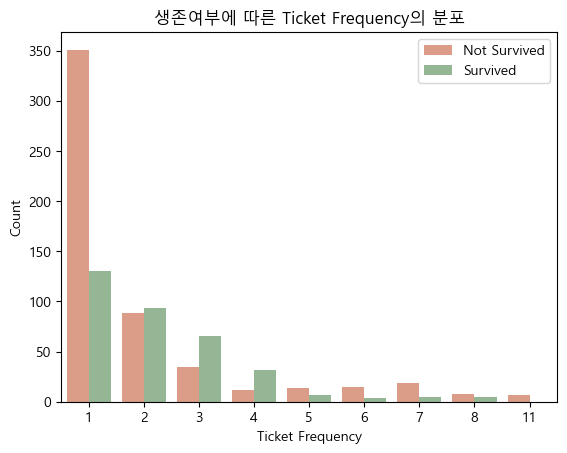
6. 피쳐 엔지니어링 결과 정리
이번 글에서 진행한 피쳐 엔지니어링 과정을 정리하면 다음과 같습니다.
각 Feature의 처리 과정
- Age열: 연속형 데이터를 Binning하여 범주화
- Embarked열: 기존 범주형 그대로 사용
- Fare열: 연속형 데이터를 Binning하여 범주화
- Name열: 승객명에서 Mr, Mrs, Dr 등을 추출하여 새로운 Feature 생성
- Parch열: SibSp열 데이터와 결합하여 새로운 Feature 생성
- PassengerId열: 각 행에 번호를 붙인 무의미한 열이므로 삭제
- Pclass열: 기존 범주형 데이터 그대로 사용
- Sex열: 기존 범주형 데이터 그대로 사용
- Ticket열: 중복된 정도를 Ticket Frequency라는 새로운 Feature로 추출
- Deck열: 기존 범주형 데이터 그대로 사용
필요없어진 Feature들을 데이터셋에서 drop하고, 새롭게 추출한 Feature들을 포함하여 새로운 상관행렬(Correlation Matrix)를 그리면 다음과 같습니다.
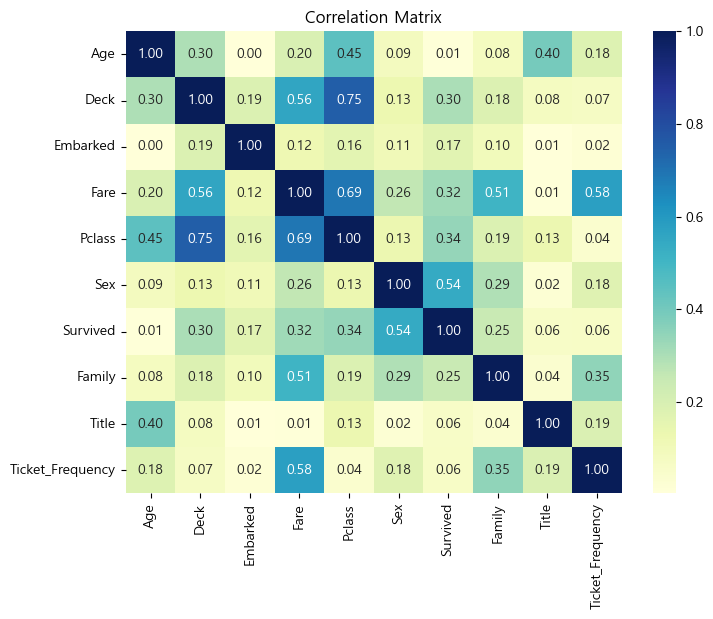
상관행렬을 살펴보면, 피쳐 엔지니어링 진행 전과 비교하여, 변수 사이의 상관관계가 더욱 뚜렷해진 것을 알 수 있습니다.
변수 사이 상관관계가 뚜렷해진 것이 반드시 좋은 현상이라고 할 수는 없겠으나, 이번 글에서는 다양한 방법을 통해 Feature Engineering을 진행했다는 데에 의의를 두도록 하겠습니닿ㅎㅎ
7. Feature Encoding: 라벨인코딩 및 원핫인코딩 진행
피쳐 엔지니어링 과정을 끝냈으니 모델 훈련에 앞서 각 Feature에 대해 Feature Encoding을 진행해야 합니다. 피쳐 인코딩은 Feature의 특징에 따라 라벨인코딩 혹은 원-핫 인코딩으로 진행하였습니다.
- 라벨인코딩: Ordinal Data인 Age열과 Fare열
- 원-핫 인코딩: Nominal Data인 Pclass열, Embarked열, Family열, Deck열, Sex열, Title열, Ticket Frequency열
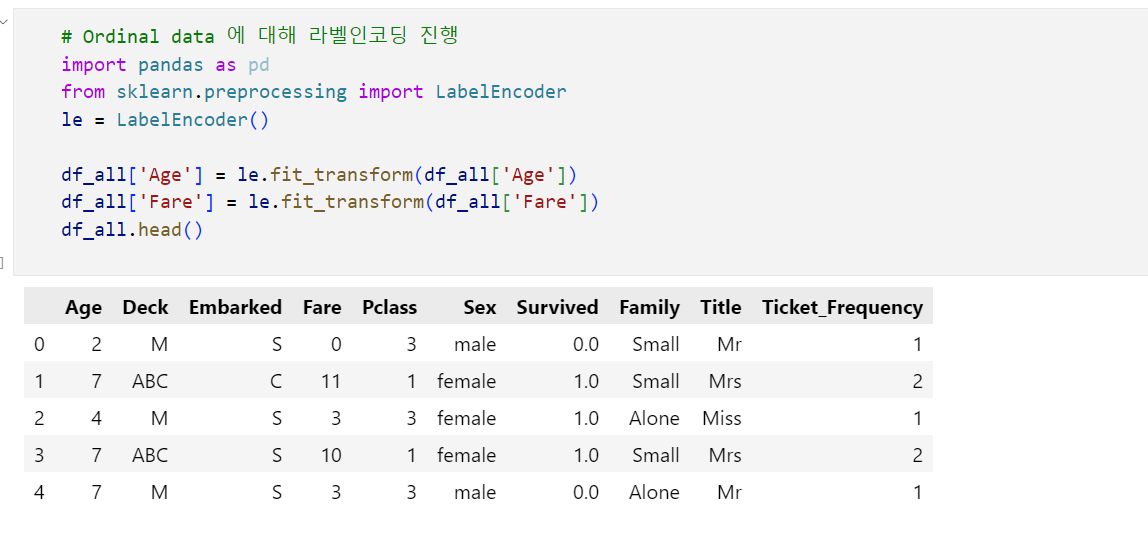
라벨인코딩의 경우 sklearn.preprocessing 에서 LabelEncoder를 불러오면 쉽게 진행할 수 있습니다.
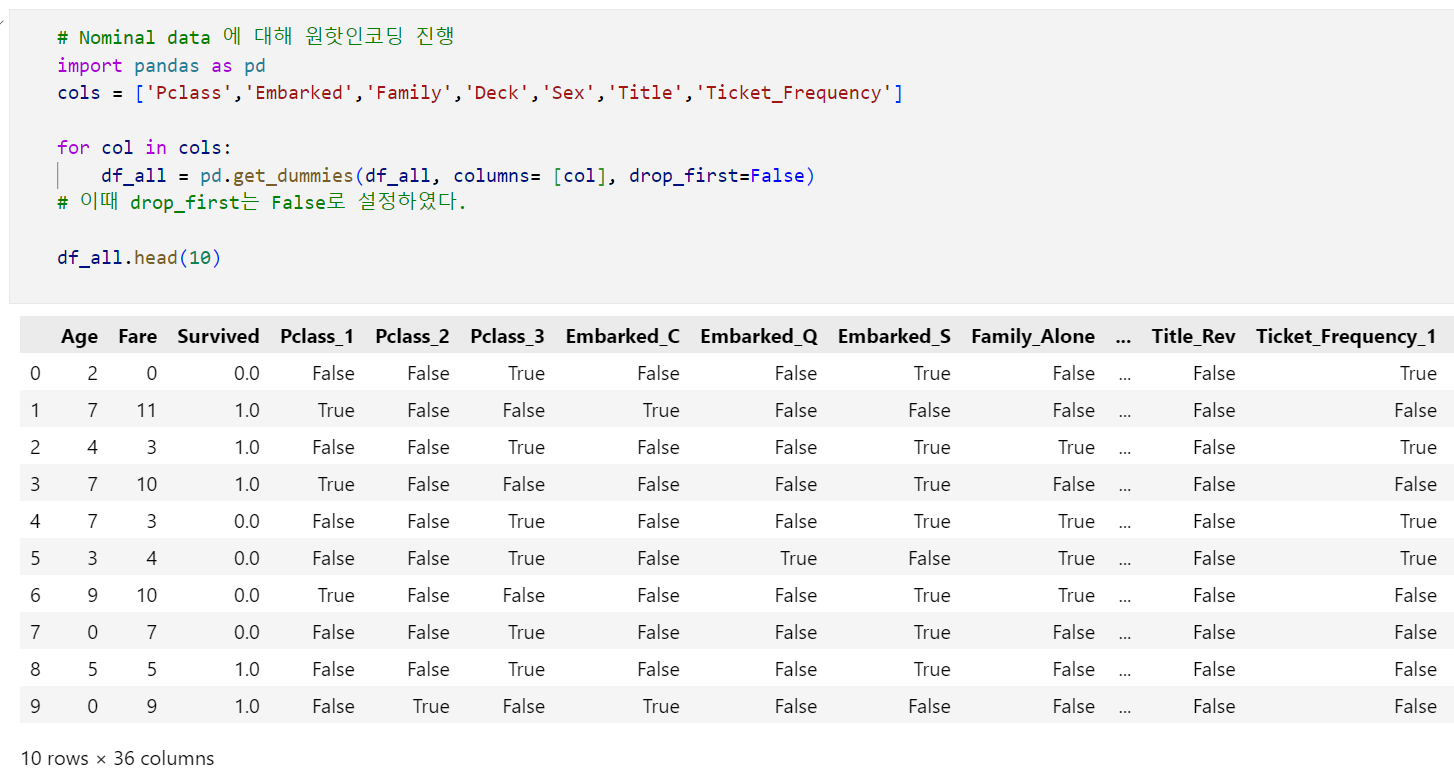
원핫인코딩의 경우에는 pd.get_dummies() 를 사용하여 진행합니다.
df_train_encoded = df_all[:891]
df_test_encoded = df_all[891:]
df_train_encoded.to_csv('titanic_train_encoded.csv', index=False)
df_test_encoded.to_csv('titanic_test_encoded.csv', index=False)
피쳐 엔지니어링이 끝난 데이터셋을 각각 titanic_train_encoded, titanic_test_encoded라는 이름으로 저장해 주었습니다.
이로서 지난 글에서부터 이번 글까지, Titanic 데이터셋에 대해 각각 전처리와 피쳐 엔지니어링을 진행해 보았습니다. 다음 글에서는 모델 구축 및 모델 평가를 진행해보도록 하겠습니다.
밑의 코드는 Titanic 피쳐 엔지니어링을 다룬 글 중에서 가장 코드가 간결한 글이라 참고용으로 올립니다!!
[Kaggle] Titanic 생존자 예측 ② Feature Engineering & 모델링
Titanic 생존자 예측 ② Feature Engineering & 모델링 3. Feature Engineering Feature Engineering을 시작하기에 앞서 상관계수, 결측치를 확인해보자 train.corr() train.isnull().sum() Train과 Test data를 한 번에 변환하기 위
seo00.tistory.com
저의 코드는 밑에 Colab에 올려두었습니다!!
https://colab.research.google.com/drive/12t0u1C-hL2IOGX99J4U5Le7X319Lo-PM?usp=sharing
타이타닉 시각화.ipynb
Colab notebook
colab.research.google.com
소감과 목표와 Adsp 후기 등등..
(근데 이제 새벽감성을 곁들인)
데이터분석과 머신러닝에 대해 공부할 때 저를 가장 당혹스럽게 하는 것은 이론과 실습이 주는 괴리감인 것 같습니다. 수업이나 책으로 배우는 것들보다 전 오히려 프로젝트를 진행하거나, 혹은 남이 써둔 코드를 보면서 많이 배우고 또 재미를 느꼈던 것 같아요. 아직은 남의 코드를 보고 따라하거나 챗지피티한테 물어가며 코드 쓰는 일밖에 못하지만 적어도 올해 안에는 이런 저의 실력을 조금이라도 올려보고 싶네용..
지난 글에도 쓴 내용이지만, 지난 주 Adsp 44회 시험을 보고 왔습니다. 합격 여부에 상관없이, 데이터분석 쪽 내용을 한번 쭉 훑어보면서 공부할 수 있었어서, 전반적으로 도움이 많이 되었던 것 같아요. Adsp를 공부하면서 가장 발목을 잡았던 건 역시나 통계학이었습니다. 고등학교 때 확통 버렸었는데 그때 그냥 열심히 할걸, 이라는 생각도 들고요. 여튼 앞으로 통계학..열심히...공부해볼게요오...
이상..
'데이터분석' 카테고리의 다른 글
| [데이터분석] 출퇴근 시간 지하철역 혼잡도 시각화 (0) | 2025.04.05 |
|---|---|
| [데이터분석] Titanic 데이터셋 (1): 결측치 처리 (0) | 2025.02.24 |