안녕하세요. 티스토리 블로그로 다시 돌아왔습니다.
아무래도 네이버 블로그보다는 티스토리로 갈아타는게 좋아 보였어욯ㅎㅎ
근황토크)) 몇주간 통계학이랑 Adsp 공부를 하느라 바빠서(사실 공부 안함 히히) 데이터분석이나 머신러닝 쪽 공부를 많이 못했어요.
Adsp 데이터분석 준전문가 44회 시험을 보고 왔습니다..! 풀고나서 보니 다들 어려웠다고 하더라고요. 왠지 한번에 풀리는 문제가 많이 없더라ㅋㅋㅋㅋ뭐 이번에 떨어지면 그냥 5만원 날리고 공부나 열심히 한 셈 치겠습니다. 근데 자격증 시험이 대체 뭐길래...저에게서 5만원이나 뜯어가는 걸까요.
준전문가니 뭐니 있어보이는 말들이지만 50문제중에 30문제 맞추면 자격증 주는 그런 어렵진 않은 자격증 시험이라..
뭔가 막상 떨어지면 운전면허 필기 떨어진 것마냥 그런..민망한 기분이 들 것만 같네요. (심지어 내 전공인데)
일단은 지나간 건 지나간 것들이니 기억의 저편으로 넘겨버리고 남은 할일들을 하도록 하겠습니당

목차
1. Titanic 데이터셋
1.1. Kaggle 대회 및 참고 코드
1.2. 프로젝트 목표: 데이터 전처리
1.3. 상관행렬(Correlation Matrix) 시각화
2. Age 열의 결측치 처리
3. Embarked 열의 결측치 처리
4. Fare 열의 결측치 처리
5. Cabin 열의 전처리 과정
5.1. Cabin 열의 결측치 처리 방법
5.2. Cabin 열에 따른 생존여부 시각화
5.3. Cabin 열의 범주화
6. 결론 및 시사점
1. Titanic 데이터셋
여러분들은 타이타닉 하면 뭐가 가장 먼저 떠오르시나요?
???: 레오나르도 디카프리오요.

뭐 여튼..이번에는 타이타닉 데이터셋을 이용해 전처리를 해봤습니다.
타이타닉 데이터셋이 뭐에오?? >> 대충 타이타닉호에 탑승한 승객의 정보를 통해 이 승객이 죽었나 살았나 판단하는 거에용

그치만 저는 MBTI T라서 잘 몰루겠어요,,,
원래는 Kaggle에서 진행하는 데이터 분석 대회에 나가볼까 했는데, 아직 제 실력으론 거기까지는 무리고 초보자들 위주의 데이터분석 대회인 Getting Started에서 코드 이것저것 구경하다가, 괜찮은 코드가 있어서 따라해 봤습니다.
원래의 원래는 모델 만들어서 학습 결과를 csv파일로 제출하는 것까지가 목표였는데, 일단 전처리부터 막혔기 때문에..하하하
머신러닝 모델 구축 및 평가는 다음에 진행하기로 했어요~~
1.1. Kaggle 대회 및 참고 코드
Kaggle의 Titanic 데이터 분석 Getting Started 대회는 아래에서 확인 가능합니다!!
이때 꿀팁은 Hotness가 아니라 Most Votes로 필터 설정해야 좋은 코드 구경 가능하다는 사실!!
남의 코드에 댓글도 달 수 있던데 댓글보면 뭐가 낫네 마네하면서 토론하는 사람들 구경도 가능합니다.
그리고 저기 Leaderboard 들어가면 Score가 1.00점인 사람들이 가득한데 그거 다 답지 베낀 사람들이니까 그냥 무시하시길
https://www.kaggle.com/code/gunesevitan/titanic-advanced-feature-engineering-tutorial
Titanic - Advanced Feature Engineering Tutorial
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
제가 참고한 코드는 위의 링크에 있습니다!!
타이타닉에 매우 진심인 사람인 것 같던데 정말정말 설명을 잘 써놔서 읽는 것만으로도 도움이 많이 됩니다.
전처리 과정의 대부분은 위 글의 설명을 참고했습니다.(그냥 베꼈다는 뜻)
코드.steal()
1.2. 프로젝트 목표: 데이터 전처리
위에서 소개한 타이타닉 데이터셋에 대한 전처리를 진행하는 것이 이번 목표였습니다.
이상치 처리보다는 결측치 처리를 위주로 진행하였습니다. (사실상 결측치 처리밖에 안함..)
Kaggle의 Getting Started 대회에서는 훈련데이터 파일과 테스트데이터 파일을 개별로 제공합니다. 훈련데이터를 통해 학습을 진행하고, 테스트데이터를 통해 판단한 결과를 csv 파일로 만들어 제출하라는 것이 요지입니다.
문제점은 훈련데이터 train.csv 와 테스트 데이터 test.csv에는 결측치가 존재한다는 것입니다. 확인 결과 각 데이터셋에서 결측치는 다음과 같았습니다.
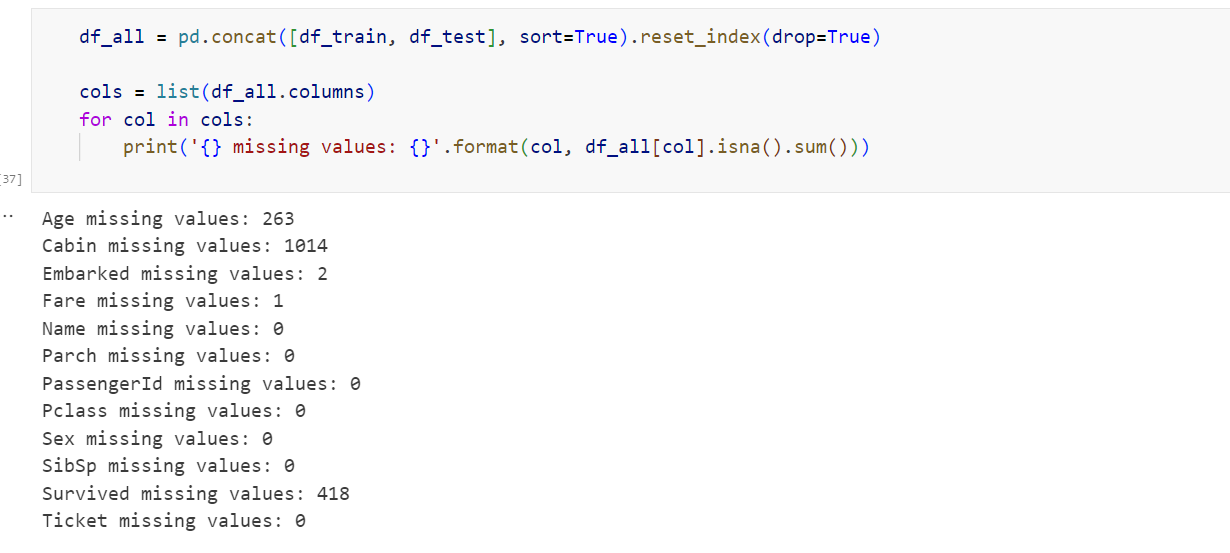
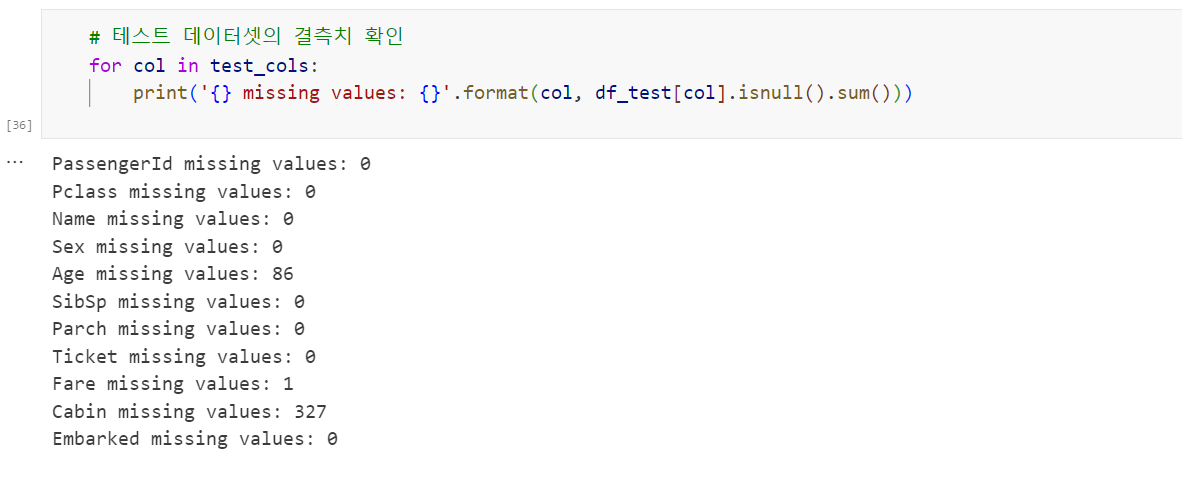

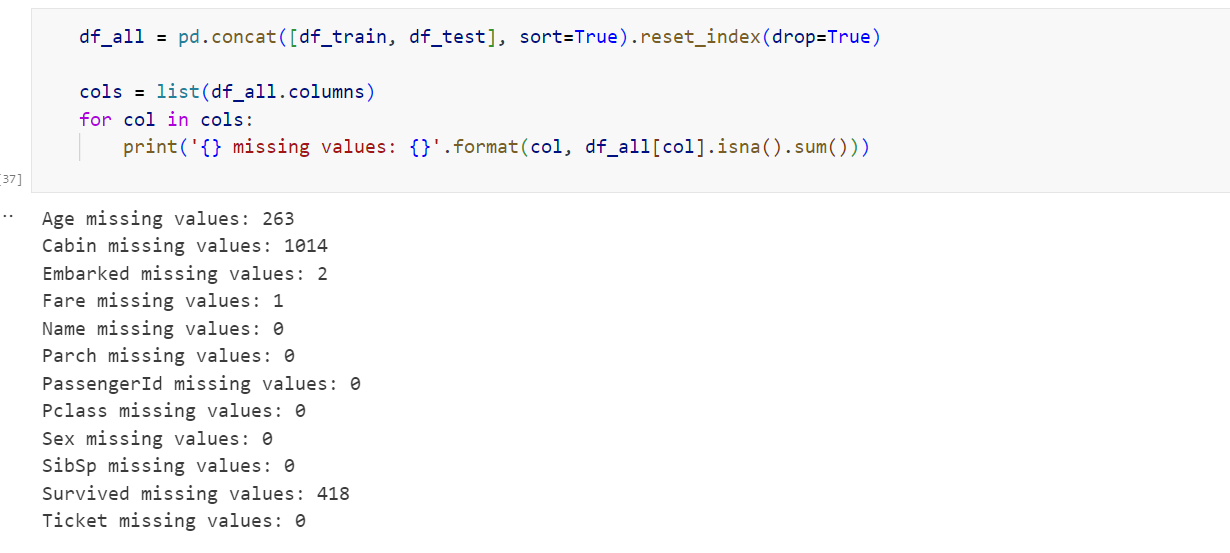
- Age 열
- Embarked 열
- Fare 열
- Cabin 열
각 열에 대해, 최대한 행 제거의 방법을 사용하지 않고,또 모델의 학습 성능을 최대한 높일 수 있도록 적절한 데이터로 결측치를 대체하는 것을 목표로 하였습니다. 더 나아가 특정 값으로 결측치를 대체하는 방법 외 다른 방법 또한 시도해 보았습니다.
1.3. 상관행렬(Correlation Matrix) 시각화
전처리를 진행하기 이전에, 적절한 결측치 처리를 위해서는 각 변수 사이의 상관관계를 알 필요가 있다고 생각했습니다. 결측치가 대부분인 Cabin열, 그리고 타겟 변수와는 무관한 열인 Name열 /PassengerId열 /Ticket열 을 삭제한 뒤, 상관행렬을 시각화한 코드 및 결과는 다음과 같습니다.
from sklearn.preprocessing import LabelEncoder
df_copy = df_all.copy()
df_copy.drop(columns = ['Cabin','Name','PassengerId','Ticket'], inplace=True)
obj_cols = df_copy.select_dtypes(include=['object']).columns
le = LabelEncoder()
for col in obj_cols:
df_copy[col] = le.fit_transform(df_copy[col])
corr_matrix = np.abs(df_copy.corr())
plt.figure(figsize=(8,6))
sns.heatmap(corr_matrix, annot=True, cmap='YlGnBu', fmt=".2f")
plt.title('Correlation Matrix')
plt.show()
결과를 보시면 높은 상관관계를 보이는 변수들이 존재합니다. 사실 전처리를 진행하기 전의 데이터를 사용하여 얻은 결과라 다소 부정확하나, 위와 같은 결과는 Age열 및 Fare열의 결측치를 대체하는 과정에서 적극적으로 사용하였습니다.
2. Age 열의 결측치 처리
Age열은 숫자형 데이터로, 이를 중앙값으로 대체하는 것이 가장 좋은 방법이라고 판단했습니다.
이번 데이터셋에서 Age열의 결측치는 263개입니다. 가장 쉬운 방법은 전체 Age 데이터의 중앙값으로 결측치를 대체하는 것이겠지만, 전체 1307개의 데이터 중 263개의 결측치를 중앙값이라는 같은 숫자로 대체하는 것은 모델의 성능을 유의미하게 떨어트릴 수 있다고 생각했습니다.
더 좋은 대체값을 찾기 위해, 위의 상관행렬에서 살펴본 결과 Age와 가장 상관관계가 높은 Pclass열을 조금 더 자세히 살펴봤습니다. Pclass에 따른 Age열 데이터의 분포를 박스플롯으로 표현하여 데이터의 분포를 살펴보면, 다음과 같습니다.

위 그래프를 보면 Pclass별로 Age의 분포가 유의미한 차이를 보인다는 것을 알 수 있습니다. 어쩌면 이것은 당연한 결과일지도 모릅니다. 탑승 승객의 나이가 많을수록, 젊은 승객(3등석)에 비해 높은 등급(1등석)을 받을 수 있을 만한 금전적인 여유가 있을 확률이 높으니까요.
cf) Boxplot을 사용하여 그룹 간 분포 차이를 비교할 수 있으나 그 차이가 유의미함을 보일 수는 없다. 평균 차이의 유의미함을 보기 위해서는 ANOVA와 같은 평균 차이 검정을 해야 한다. 는 내용을 어느정도 간과한 부분이긴 합니다. ANOVA에 대해서는 조금 더 공부해봐야겠어요.. 사실 정확하게 뭐하는건지 잘 모름.
위 결과에서, 승객 등급(Pclass)을 다시 Sex(성별이라는 뜻^^7)로 한 번 더 그룹화하여 Age의 분포를 살펴보면 흥미로운 결과를 관찰할 수 있습니다.

처음 구한 상관행렬에서는 드러나지 않았지만, Age 데이터의 분포는 Pclass와 Sex 별로 유의미한 차이를 보입니다. 따라서 "전체 Age데이터의 중앙값"으로 결측치를 대체하는 것보다, "Pclass 및 Sex 그룹별 Age 데이터의 중앙값"으로 결측치를 대체하는 것이 좋아 보입니다.
추가로, 위의 박스플롯을 보면 3등급 승객의 경우 다수의 이상치들이 존재하므로, 평균값보다는 중앙값을 사용하는 편이 좋을 것이라고 판단하였습니다.
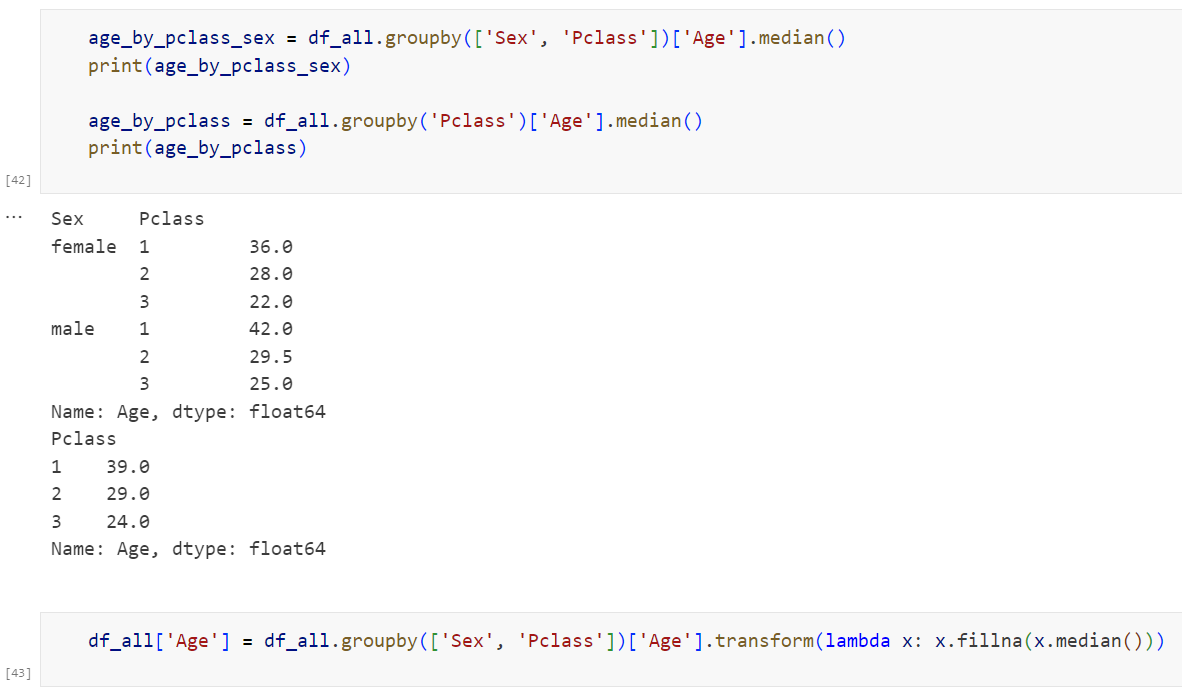
실제로 그룹별 중앙값을 구해 보면 많은 차이가 있습니다. 그룹별로 구한 중앙값으로 결측치를 대체해 주었습니다.
3. Embarked 열의 결측치 처리
주어진 데이터셋에서 Embarked 열의 경우 결측치가 딱 2개입니다. 대부분의 타이타닉 전처리 튜토리얼에서는 이를 최빈값인 S로 대체합니다. 실제로 Embarked열의 데이터 분포를 살펴보면 S 레이블의 빈도수가 압도적으로 높으므로, 이를 최빈값으로 대체하는 것도 적절한 방법으로 볼 수 있습니다.

결측치를 처리하기 위해 주어진 두 개의 결측치를 확인해봅니다.

결측치가 있는 행의 승객명을 살펴보면 Martha Evelyn 과 Miss.Amelie입니다. 이 사람들의 이름을 구글에 검색해보면 매우 흥미롭게도 관련 정보가 나옵니다.

설명을 읽어보면 두 사람은 일행이며, 모두 Southampton('S')에서 탑승했음을 확인할 수 있습니다. 따라서 'S'라는 정확한 정보로 결측치를 처리할 수 있습니다. 결측치 처리라기보다는 결측치에 해당하는 정확한 데이터를 찾아냈다고 보는 것이 맞을 것 같습니다. 결측치에 해당하는 데이터를 직접 검색하여 알아낼 생각을 했다니 대단한 것 같습니다..
4. Fare 열의 결측치 처리
주어진 데이터셋에서 Fare열의 결측치는 1개입니다. Fare열은 숫자형 데이터이기에 이전 글의 '2.Age열의 결측치 처리'와 비슷한 방법으로 결측치 처리를 진행하였습니다.
1.3.에서의 상관행렬을 참고하면 Pclass, Embarked, Parch 순으로 상관관계가 높은 것을 확인할 수 있습니다. Age열에서는 승객 나이 데이터를 Pclass별 Sex별 그룹으로 나눈 뒤 해당 그룹의 중앙값을 결측치 대체값으로 선정하였습니다. 비슷하게, Fare열에서는 Pclass별 Embarked별 Parch별 그룹으로 데이터를 나눈 뒤 해당 그룹의 평균값으로 결측치를 대체하였습니다.
설명이 조금 복잡했는데 밑의 코드로 간단하게 요약 가능합니다.

Mr.Thomas씨께서는 사우스햄프턴에서 일행 없이 3등석을 탑승하셨기에 "사우스햄프턴에서 일행없이 3등석에 탄 사람" 들의 티켓 가격 평균값으로 Fare 행을 대체하였다고 이해하면 됩니다.
여기까지가 Age열, Embarked열, Fare열의 결측치 처리 과정이었습니다.
5. Cabin 열의 결측치 처리
Cabin 열은 타이타닉 데이터셋에 있어서 가장 골때리는 부분이 아닐까 생각합니다.
결측치의 개수가 터무니없이 많기 때문이죠. 이번 데이터셋의 경우(훈련데이터와 테스트 데이터 포함) 총 1309개의 데이터 중 Cabin 열은 무려 1014개가 결측치입니다.
그래서 보통은 Cabin열은 열 전체를 삭제하는 방식으로 전처리를 진행합니다. 전처리를 처음 접했을 때의 저도 아무 생각 없이 Cain열을 삭제했었어요. 다른 사람들은 어떻게 Cabin열의 전처리를 하는지 궁금해서 이것저것 찾아봐도 거의 대부분 Cabin열 전체를 삭제하는 식으로 처리를 하더라고요.
(밑의 링크는 그냥 참고용...이분도 그냥 Cabin열은 삭제하심)
[Kaggle] 타이타닉 생존자 예측 1부 - EDA(3)
안녕하세요. 천선생입니다. 지난 포스트에서는 Sex, Age, Sibsp / Parch 변수에 대한 탐색을 다뤘는데요. 지나치셨다면 아래 링크를 통하여 확인하시길 바랍니다! https://cheon9.tistory.com/21 [Titanic] 타이타
cheon9.tistory.com
그런데, Cabin 열을 그냥 삭제해버려도 괜찮을까??
밑의 사진은 제가 참고한 코드의 작성자가 쓴 Cabin열에 대한 설명입니다. 작성자는 Cabin열을 'little bit tricky but needs further exploration'이라고 표현하는데, 요지는 결측치가 많긴 하나 탑승 객실 별로 생존여부가 크게 갈릴 수 있으니 무시할 수 없는 정보라는 것입니다.

저도 위 설명을 읽기 전까진 Cabin 열을 그냥 삭제하는 것에 대해 아무런 자각을 하지 못했는데, 생각해보면 타이타닉 탑승 승객의 생존 여부를 판단하는 것이 최종적인 목표인 데이터분석에서, 가장 생존 여부와 직결되는 정보인 탑승 선실의 데이터를 배제하는 것은 매우 심각한 일입니다.
그러므로 Cabin열의 전체 데이터를 삭제한 뒤 모델 학습을 하는 것보다, 적은 양의 데이터일지라도 적절한 전처리 과정을 통해 탑승 선실 정보를 최대한 보존하는 것이 중요하다고 생각하였습니다.
5.1. Cabin 열의 결측치 처리 방법
Cabin열에 저장된 데이터를 살펴보면 저렇게 생겼습니다.(아래 사진 코드 참고) '탑승객실+일련번호'의 형태로 되어있죠. 여기서 타겟열과 무관한 데이터(노이즈)인 '일련번호'부분은 제외하고, '탑승객실'의 정보만을 뽑아내는 것이 우선입니다.

그럼 결측치 데이터들은 어떻게 하냐고요? 결측치가 있는 데이터에는 'M'(M for missing) 이라는 새로운 레이블을 부여하였습니다. 즉, 결측치를 '기존에 존재하는 레이블로 대체하는 것'이 아닌, '결측치인 데이터 자체를 또 하나의 레이블'로 바라보는 것입니다.
이렇게 정리된 '탑승 객실'의 정보는 Cabin이라는 열이 아닌 Deck이라는 이름의 새로운 열을 만들어 저장하였습니다. 코드는 생각보다 간단합니다!

이제 승객들의 탑승 객실에 대한 정보는 Deck열에 문자열 형태로 저장되어 있습니다. df_all['Deck'].unique() 부분을 확인하면, 이 열은 M,A,B,C,D,E,F,G,T 레이블을 가짐을 확인할 수 있습니다.
결측치를 대신하여 새로 만든 M이라는 레이블에 대해 조금 더 살펴보겠습니다.

Deck별 Pclass의 분포(탑승 객실별 탑승 등급 분포) 를 살펴보면 다음과 같습니다. M 레이블의 대부분이 3등석 승객이며, 3등석과 2등석이 대다수를 차지한다는 사실을 알 수 있습니다. 다르게 말하면 2등석 승객과 3등석 승객의 경우 대부분 승객의 탑승 객실에 대한 정보가 누락되어 있었다는 뜻도 됩니다.
5.2. Cabin 열에 따른 생존여부 시각화
위에서 승객의 탑승 객실이 해당 승객의 생존 여부와 직결될 것이라고 예상했었습니다. 정말 그런지 전처리 후 결과를 막대그래프로 시각화하면 다음과 같습니다.

그래프를 살펴보면, M 레이블에서 특히 생존 승객의 비율이 적음을 확인 가능합니다. 이는 '탑승 선실에 대한 정보가 누락된 승객(=M 레이블 승객)의 60% 이상이 사망하였다.'는 중요한 정보를 제공합니다. 또 다른 흥미로운 점은 B,D,E 객실의 경우 생존한 승객의 비율이 비슷한 정도로 높다는 것입니다.
위처럼 전처리 진행 후 Cabin열(=Deck열)과 생존 여부의 관계를 살펴보면, 유의미한 차이를 확인 가능합니다. 이를 통해, Cabin 열을 삭제하는 것보다, 적절한 전처리 과정을 통해 탑승 선실에 대한 정보를 제공하는 편이 더 좋은 모델 성능을 기대할 수 있다, 고 결론내릴 수 있겠습니다.
이로써 타이타닉 데이터셋의 모든 열에 대한 전처리가 끝이 났습니다!!
5.3. Cabin 열의 범주화
Cabin열을 조금 더 효율적으로 표현하기 위해, Pclass의 비율을 기준으로 범주화하는 과정을 추가하였습니다. 바로 위에서 살펴본 'Deck별 Pclass 분포'를 다시 한 번 살펴봅시다.

Pclass분포에 대해 살펴볼 때, A,B,C 레이블/ D,E 레이블/ F,G 레이블 은 비슷한 특징을 보입니다. 비슷한 특징을 가진 레이블을 묶어 이를 'ABC', 'DE', 'FG'라는 새로운 레이블로 처리하는 과정을 거쳤습니다.
df_all['Deck'] = df_all['Deck'].replace(['A','B','C'], 'ABC')
df_all['Deck'] = df_all['Deck'].replace(['D','E'], 'DE')
df_all['Deck'] = df_all['Deck'].replace(['F','G'],'FG')Cabin 열의 범주화 이전과 이후를 비교해보면 다음과 같습니다. 확실히 범주화 이후의 결과가 조금 더 잘 다가오는 것 같아 보이지 않나요? 이와 같은 범주화 과정은 다음 글의 '피쳐 엔지니어링' 부분에서 조금 더 자세히 다룰 예정입니다.

6. 결론 및 시사점
우선 결측치 처리가 모두 끝난 데이터셋(df_all)을 다시 훈련 데이터셋(df_train)과 테스트 데이터셋(df_test)로 분할해 주었습니다. 이후 훈련데이터에 대해 다시 한 번 상관행렬(Correlation Matrix)를 그려 보았습니다.


처음 전처리 과정 전 그린 상관행렬과 비교해보면 위와 같습니다. 타겟열인 Survived만 살펴본다면, 상관계수 자체는 전처리 전과 후에 큰 변화는 없습니다. 그러나 전처리 과정을 통해 처음에는 노이즈에 불과했던 Cabin열을 0.30의 상관관계를 보이는 유의미한 Deck열로 성공적으로 변환했음을 알 수 있습니다.
결론 및 시사점
- 일반적으로 사용하는 결측치 대체(평균값 대체, 중앙값 대체) 등의 방법 외 다른 참신한 방법으로 결측치 처리를 할 수 있다는 사실을 알게 되었다.(Embarked열에서 직접 정보를 검색하여 데이터를 알아내거나, 혹은 Cabin열에서 결측치 자체에 새로운 레이블을 부여함.)
- 평균값이나 중앙값으로 단순히 결측치를 대체하는 과정에서도, 다른 변수와의 상관관계를 고려하여 조금 더 나은 방법으로 결측치를 대체할 수 있음도 알게 되었다. (Age열에서 전체 중앙값이 아닌 그룹별 중앙값을 사용함.)
- 무조건 근거를 가지고 전처리를 진행하는 것이 모델의 학습 결과 향상으로 이어지지는 않는다. (=전처리에 정답은 없다.) 그러나 데이터에 대한 충분한 분석을 진행하며 전처리를 하는 것이 모델의 능력 향상으로 이어질 확률이 높을 것이다.
결론: 전처리는 중요하다...
소감 등등...
전처리 맨날 끄적이기만 하다가 제대로 해보는 건 이번이 처음인데, 생각보다 어려운 과정임을 꺠달았습니다. 데이터셋 여러 개 끄적일 바에야 그냥 데이터셋 하나 정해서 끝까지 전처리 진득하게 진행해보자,는 생각으로 시작했는데 막상 시작하고 보니 끝이 없었어요...여태까지 내가 해온 전처리는 대체 무엇이었단 말인가,,
남이 올린 코드 그냥 무작정 따라해본 건데 생각보다 얻을 것이 많았습니다! EDA 쪽도 쪼끔은 건드려본 것 같은 기분인데 다음에 기회되면 조금 더 공부해보겟음,,
일단은 전처리까진 끝냈으니 이후에 적절한 모델 선정 및 학습 진행까지 시도하는게 목표고요, Kaggle 사이트에 분석 결과 파일을 올리는 것까지가 최종 목표이긴...하나 Adsp 공부 때문에 미뤘습니다.
참고 코드가 정말 도움이 많이 되었습니다!! 밑에 링크 다시 둘테니까 정말 한번만 읽어보세요!! (영어인건 안비밀..읽느라 힘들엇따)
참고코드 링크입니다. EDA랑 결측치 처리부터 모델 구축 과정까지 자세히 설명해둠,,
https://www.kaggle.com/code/gunesevitan/titanic-advanced-feature-engineering-tutorial
Titanic - Advanced Feature Engineering Tutorial
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
제 코드는 아래 Colab에서 확인 가능합니다!!
https://colab.research.google.com/drive/1Aw0aFRF4Z2aykPy7UQ-kjtFpbdX05WWs?usp=sharing
타이타닉 전처리.ipynb
Colab notebook
colab.research.google.com
이상!! 긴 글 읽어주셔서 감사합니다!
'데이터분석' 카테고리의 다른 글
| [데이터분석] 출퇴근 시간 지하철역 혼잡도 시각화 (0) | 2025.04.05 |
|---|---|
| [데이터분석] Titanic 데이터셋 (2): 시각화 & 피쳐 엔지니어링 (1) | 2025.02.25 |